Apache Chukwa
Big Data Processing and Distribution subtitle
Apache Chukwa Alternatives
The best Apache Chukwa alternatives based on verified products, community votes, reviews and other factors.
Latest update:
-
/amazon-emr-alternatives

Amazon Elastic MapReduce is a web service that makes it easy to quickly process vast amounts of data.
-
/google-cloud-dataflow-alternatives

Google Cloud Dataflow is a fully-managed cloud service and programming model for batch and streaming big data processing.
-
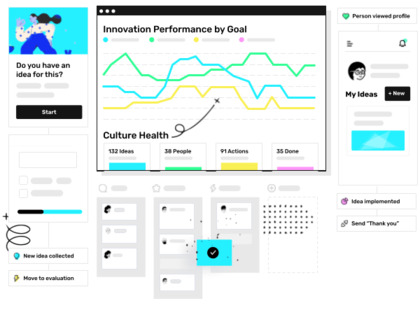
Try for free

Ideanote is the #1 rated Idea Management solution for companies of all sizes. Collect, develop and manage more of the right ideas from customers and employees to drive your growth.
-
/looker-alternatives

Looker makes it easy for analysts to create and curate custom data experiences—so everyone in the business can explore the data that matters to them, in the context that makes it truly meaningful.
-
/apache-avro-alternatives

Apache Avro is a comprehensive data serialization system and acting as a source of data exchanger service for Apache Hadoop.
-
/apache-hbase-alternatives

Apache HBase – Apache HBase™ Home
-
/hadoop-alternatives

Open-source software for reliable, scalable, distributed computing
-
/apache-mahout-alternatives
Distributed Linear Algebra
-
/apache-tez-alternatives

Apache Tez is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data.
-
/apache-giraph-alternatives

Graph Databases
-
/apache-spark-alternatives

Apache Spark is an engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing.
-
/apache-flink-alternatives

Flink is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations.
-
/apache-pig-alternatives

Pig is a high-level platform for creating MapReduce programs used with Hadoop.
-
/apache-hive-alternatives

Apache Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage.